
Aunque la explosión de información nos brinda la oportunidad de elegir entre una amplia gama de recursos, también ha suscitado inquietud sobre cómo abrirnos paso entre el ruido y centrarnos en los temas y tendencias concretos que nos interesan. Para ello, es posible que haya optado por seguir tus blogs y sitios de noticias favoritos en un lector RSS. Pero cuando te encuentras con un sitio que no tiene la opción de RSS de texto completo, ¿qué haces?
En este artículo, te presentaremos algunos raspadores de artículos fáciles de usar para descargar blogs y noticias (por ejemplo, un Medium Scraper). Le guiaremos en la configuración de un raspador de artículos personalizado que pueda recopilar de forma rápida, eficaz y reproducible todos los artículos que necesite, sea cual sea su longitud. ¿No tiene RSS? No hay problema.
Los 3 Mejores Raspadores de Artículos
Restringir los mejores raspadores de artículos del mercado no es tarea fácil cuando hay tantas opciones diferentes entre las que elegir. Lo importante es recordar que no existe una única opción, sino el mejor software que se adapte a sus necesidades de datos, lo que depende de su presupuesto, preferencias de interfaz de usuario, frecuencias de raspado y nivel de experiencia.
La buena noticia es que, tanto si es un principiante que desea configurar su primera tarea de scraping como si es un experimentado minero de datos que desea actualizar tu experiencia de scraping, sin duda existe una herramienta para ti.
Hemos probado más de diez herramientas de raspado web y, a continuación, encontrará nuestras recomendaciones de las tres mejores del mercado para el raspado de artículos. Estas opciones se seleccionaron no sólo en función de su conjunto de funciones de raspado de artículos, sino también de su rendimiento general.
1. Octoparse
Octoparse es una herramienta de web scraping que permite extraer datos de múltiples sitios web sin necesidad de código. Puede imitar el comportamiento de navegación humano y raspar artículos y publicaciones de cualquier sitio web en cuestión de minutos.

Interfaz de apuntar y hacer clic Octoparse viene con una interfaz de usuario fácil de usar. Le permite interactuar con tus nuevos sitios favoritos en su navegador incorporado con acciones de apuntar y hacer clic. Por lo tanto, es más fácil de dominar que la mayoría de las herramientas de raspado.
Características avanzadas Octoparse tiene un montón de características de gran alcance para ayudarle a superar los obstáculos para el raspado de artículos. Por ejemplo, si desea scrapear artículos de Medium, Octoparse puede hacer frente fácilmente a desafíos como problemas de inicio de sesión, búsquedas de palabras clave, desplazamiento infinito y muchos más.
Multiplataforma Como software gratuito basado en cliente, Octoparse es compatible tanto con Windows como con Mac. Sólo tiene que descargar e instalar Octoparse desde tu sitio web oficial y probar algunas de las plantillas listas para usar para el rastreo de artículos. Visite tu portal de autoservicio para obtener tutoriales si decide crear un rastreador web personalizado por tu cuenta.
Aceleración y programación Octoparse viene con un modo boost que mejora enormemente la velocidad de raspado de artículos tanto en dispositivos locales como en la nube. Si desea obtener artículos o publicaciones actualizados de forma rápida y sencilla, Octoparse no le defraudará. Los raspadores en Octoparse también se pueden programar para ejecutarse cada hora, cada día o cada semana para obtener artículos entregados regularmente ya sea en tu dispositivo local o utilizando tu plataforma basada en la nube.
Servicio de atención al cliente El equipo de Octoparse también ofrece un gran servicio de atención al cliente y se dedica a ayudarle con todo tipo de necesidades de datos. Si SaaS no es lo tuyo, también tienen un servicio gestionado que ofrece una solución integral para todas tus necesidades de datos.
2. WebHarvy
WebHarvy es otro software de raspado de artículos basado en el cliente que requiere el sistema operativo Windows para funcionar. Se puede utilizar para raspar directorios de artículos y comunicados de prensa de sitios web de relaciones públicas.
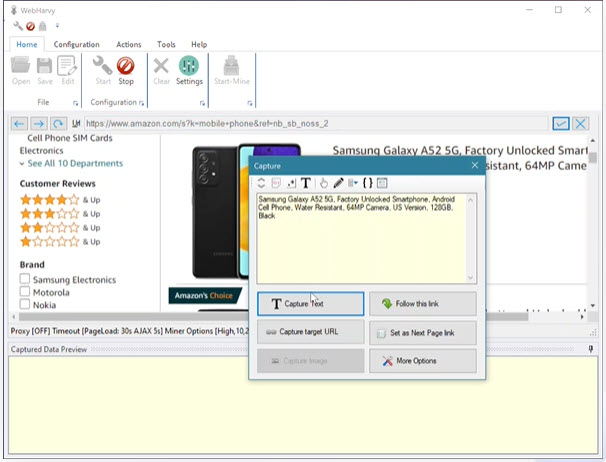
Simple Explainer Series Puede consultar los vídeos explicativos en el sitio web oficial de WebHarvy sobre cómo crear una tarea para raspar el título, el nombre del autor, la fecha de publicación, las palabras clave y el cuerpo del texto de un artículo. Si usted es nuevo en el web scraping, pueden ser un buen punto de partida.
Evaluation Versión Es muy recomendable que descargue y pruebe su versión de evaluación y compruebe los vídeos de demostración básica para comenzar su viaje de datos. Es muy fácil de usar y también soporta proxies y scraping programado. Si puede satisfacer sus necesidades de datos, puede adquirir una licencia monopuesto de WebHarvy por sólo 139 $. Usted obtiene soporte gratuito y actualizaciones gratuitas durante un período de 1 año.
3. ScrapeBox – Complemento de raspado de artículos
ScrapeBox, una de las herramientas SEO más potentes y populares, cuenta con un complemento Article Scraper que permite recopilar miles de artículos de varios directorios de artículos populares.
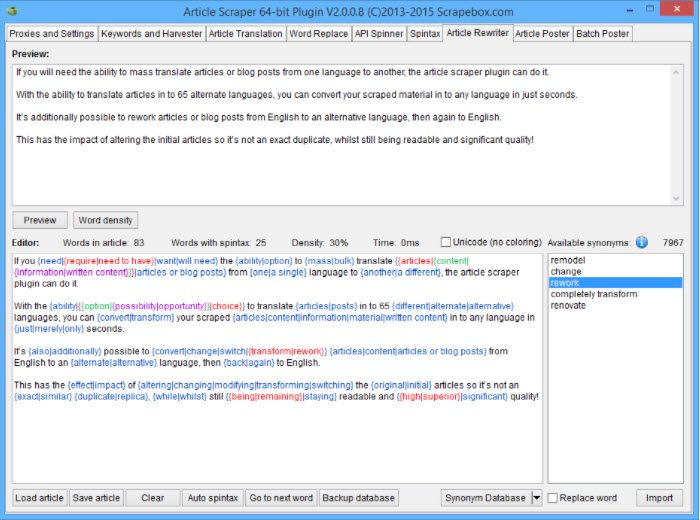
Complemento ligero Como complemento ligero, el complemento de raspador de artículos de ScrapeBox cuenta con (1) soporte de proxy, (2) multi-threading para una rápida recuperación de artículos, (3) la capacidad de establecer cuántos artículos raspar antes de detenerse, y (4) los artículos se pueden guardar en formato ANSI, UTF-8 o Unicode para que se puedan cosechar artículos en cualquier idioma.
Filtro basado en palabras clave También existe la opción de eliminar automáticamente los enlaces y las direcciones de correo electrónico de los artículos, y la posibilidad de guardar los artículos en subcarpetas basadas en palabras clave para que, al recopilar artículos para numerosas palabras clave simultáneamente, todos sus artículos estén categorizados.
Plugin Avanzado ScrapeBox también ofrece un plugin avanzado de Article Scraper que puede publicar artículos, girar artículos, traducir artículos, y mucho más.
Raspar artículos de una publicación de Medium
Para explicar mejor cómo funciona un raspador de artículos, vamos a raspar datos de artículos de la publicación Towards Data Science Medium utilizando Octoparse. Asegúrese de descargar la última versión de Octoparse antes de empezar.
Utilice el siguiente enlace como ejemplo para continuar: https://towardsdatascience.com/
Paso 1
Ingresar URL(s) en el navegador integrado de Octoparse
Cada workflow en Octoparse comienza introduciendo una página web para empezar. Basta con introducir la URL de muestra en la barra de búsqueda de la pantalla de inicio y esperar a que la página web se renderice.
Paso 2
Añadir un bucle de desplazamiento de página – para hacer frente a la página de desplazamiento infinito
Medium está diseñado para cargar contenido dinámicamente con su patrón de desplazamiento infinito. Así que tenemos que añadir un elemento de bucle en la sección de workflow. En la pestaña general del elemento de bucle, establece el modo de bucle para desplazar la página y repetir el desplazamiento hasta el final de la página 20 veces.
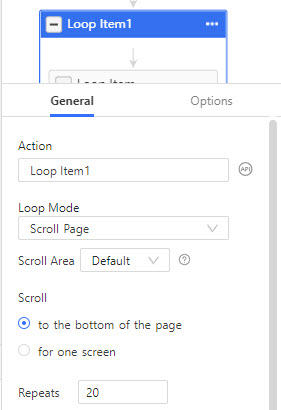
Paso 3
Extraer datos de la página de la lista de artículos
Antes de recoger el contenido de cada artículo, necesitamos recoger algunos metadatos de la página de la lista. Haga clic en el primer bloque de artículos de la lista y elija Seleccionar subelementos > Seleccionar todo > Extraer datos para recopilar los datos de la lista de artículos. Cambie el nombre de los campos de datos y elimine los no deseados, lo que nos deja con el autor, el título, la descripción, la etiqueta y la longitud de los artículos.
Además, podemos capturar las URL de los artículos utilizando el localizador XPath.
- Haga clic en añadir un campo personalizado en la sección Vista Previa de datos y seleccione scrapear datos en la página web
- Marque Relative XPath e introduzca //a[@aria-label=”Post Preview Title”]
- Guarde y Ejecute la tarea padre para obtener el primer lote de datos (tarda unos minutos)
Paso 4
Utilizar la lista de URL para una segunda tarea para obtener el texto completo
A continuación, necesitamos crear una tarea hija con las URLs de la última ejecución de datos.
- Vuelva a la pantalla de inicio de Octoparse, haga clic en +Nuevo y seleccione Modo avanzado.
- Para las URL de entrada, seleccione Importar desde la tarea y localice el campo de datos URL de la primera tarea.
- Añada una acción Extraer datos en el bucle URLs
- Haga clic en añadir un campo personalizado en la sección Vista previa de datos y seleccione scrapear datos en la página web.
- Marque XPath absoluto e introduzca //article para localizar el artículo completo
Paso 5
Guarde y ejecutar la tarea para obtener el segundo lote de datos

Te habrás dado cuenta de que hemos dividido la tarea en dos subtareas. Con ello pretendemos aumentar la velocidad de scraping de todo el proyecto. Si se trata de un proyecto complicado, se recomienda dividirlo en subtareas y ejecutarlas en la plataforma basada en la nube de Octoparse para aumentar la velocidad. También puede programar sus tareas para que se ejecuten cada hora, cada día o cada semana y recibir los datos con regularidad.
Si tiene problemas para averiguar cómo construir la tarea por su cuenta, puede ponerse en contacto con el equipo de soporte de Octoparse para obtener ayuda.
¡Diviértete haciendo scraping desde Medium!





发表回复