
Se ha vuelto imposible ocultar datos previamente ocultos. Muchas herramientas avanzadas ahora pueden extraer nuevos datos o incluso extraerlos de varias fuentes en Internet. Un análisis más profundo ha permitido a los fondos de cobertura explotar una fuente alfa importante nueva y en crecimiento.
A principios de año, Greenwich Associates y Thomson Reuters colaboraron en un estudio para ofrecer un conocimiento sobre los tremendos cambios en el panorama de la investigación de inversiones. Con el título, “El futuro de la Investigación de Inversiones“, contiene muchos factores contribuyentes que respaldan este cambio cualitativo y tiene algunas observaciones específicamente informativas sobre datos alternativos.
La importancia de los conjuntos de datos alternativos había sido revisada previamente; estos incluyen datos de geolocalización e imágenes satelitales, están demostrando que cubren fondos hay un montón de alfa sin explotar en estos conjuntos de datos para instituciones listas para invertir su dinero en su adquisición, para que puedan aprovechar las ventajas de información importante en la competencia.
Según el estudio de Greenwich/Thomson Reuters, está claro que la empresa de inversión promedio invierte alrededor de $900,000 en datos alternativos anualmente, mientras que sus datos alternativos tienen una estimación de los presupuestos anuales de la industria actualmente en torno a $300 millones. Esto es casi dos veces más que el año anterior. En base a estos datos, web-scraped data se han identificado como los datos más populares adoptados por los profesionales de inversión.

Fuente:
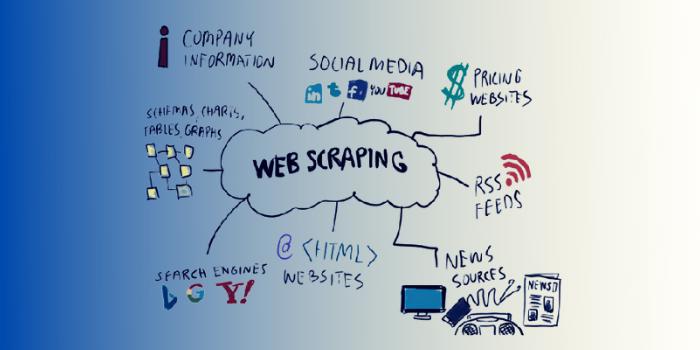
En el proceso de web scraping (considerado como “data scraping”, “spidering” o “Extracción de datos automatizada”), el software se utiliza para extraer datos que son potencialmente valiosos de fuentes en línea. Mientras tanto, para los fondos de cobertura, tener que pagar a las empresas para obtener estos datos en particular puede ayudarlos a tomar decisiones de inversión más inteligentes y razonables, incluso antes que sus competidores.
Quandl es un ejemplo de una empresa así y ahora es el centro de atracción en la revolución de los datos alternativos. Lo que hace esta compañía canadiense es scrape la web para compilar conjuntos de datos, o colaborar con expertos en dominios, y luego ofrecer los datos a la venta a los fondos de cobertura, así como a otros clientes que muestran interés.
Hay muchas formas de web-scraped data según lo informado por Greenwich, que incluyen información de redes de expertos, precios de productos, datos de tráfico web y tendencias de búsqueda.
Un ejemplo es cómo Goldman Sachs Asset Management scrape el tráfico web de Alexa.com, que pudo reconocer un aumento vertiginoso en las visitas al sitio web HomeDepot.com. El administrador de activos pudo adquirir las acciones antes de que la compañía aumentara su perspectiva y cosechar los beneficios cuando sus acciones finalmente se aprecian.
Entre sus diversas estrategias, una compañía de datos alternativa, Eagle Alpha, scrape datos de precios de grandes minoristas; y esto ha demostrado ser valioso en la provisión de un indicador direccional para las ventas de productos de consumo. Por ejemplo, cuando los datos se obtienen de sitios web de electrónica en los Estados Unidos, la compañía puede observar que los productos GoPro están disminuyendo su demanda y, por lo tanto, la conclusión correcta es que el fabricante de la cámara de acción no alcanzará los objetivos 2015Q3. Más del 68 por ciento de las recomendaciones fueron comprar las acciones dos días antes de que se declarara públicamente el bajo rendimiento de GoPro.
El valor de los datos de las redes sociales no puede ser subestimado. Es el conjunto de datos más grande que nos ayuda a comprender el comportamiento social y las empresas están scraping activamente estos datos para descubrir su valor oculto.
Según un informe reciente de Bloomberg, “El flujo de Twitter proporciona conjuntos de datos alternativos muy grandes y saludables, particularmente para los investigadores que buscan alpha”, el servicio de Bloomberg’s noticias recién lanzado toma en las noticias relacionadas con finance-related twitter feed y escaneó valiosos tweets de noticias para perspectivas de inversión. Énfasis adicional
Por el valor de los datos de las redes sociales, se descubrió que “los movimientos de Dow Jones pueden predecirse mediante estados de ánimo colectivos obtenidos directamente de los feeds a gran escala de Twitter, con una precisión de alrededor del 87,6 por ciento.
EY lanzó una encuesta en noviembre de 2017 y descubrió que los datos de las redes sociales estaban siendo utilizados o utilizados por más de una cuarta parte de los fondos de cobertura en sus estrategias de inversión dentro de 6-12 meses. Los proveedores obtienen personalmente los datos de fuentes como Facebook, YouTube y Twitter, o, a veces, a través de herramienta de web scraping como Octoparse.
Cuando los sitios web populares a los que se puede acceder fácilmente, como Amazon y Twitter, activamente be scrapped. Los fondos de cobertura se impulsarán a buscar regularmente fuentes de datos nuevas y especiales para sacar a la luz, señales comerciales precisas para permanecer en la cima de su juego. Por esta razón, no habrá fin a cuán profundamente pueden profundizar las empresas. La dark web puede incluso estar incluida.
Los datos scraped pueden incluso incluir datos de clientes o individuos, especialmente los que pueden extraerse de diferentes fuentes, como antecedentes penales, registros de vuelo, directorios telefónicos y registros electorales. Con base en los argumentos que giran en torno a los problemas con los datos personales que ganaron popularidad este año, particularmente con el surgimiento del escándalo de Cambridge Analytica en Facebook, los scrappers pronto encontrarán una fuerte oposición de los promotores de leyes de privacidad de datos.
Tammer Kamel, CEO y Fundador de Quandl, ha declarado recientemente que existe una “healthy paranoia” entre las diferentes organizaciones para eliminar la información personal antes de las ventas de los conjuntos de datos alternativos de su empresa, y ese paso en particular puede acarrear graves consecuencias. En cualquier caso, la protección reglamentaria adecuada es primordial en este nivel. Esto implica que se puede recopilar demasiada información con respecto a un individuo, ya que todavía no tenemos un conjunto de normas de gobierno.
El año pasado, el Informe de Ley de Hedge Fund declaró que “a pesar de que el comercio electrónico ha madurado relativamente, la recolección automática de datos aún no es legal. En la medida en que han surgido muchos casos para analizar disputas de scraping. Debido con los estatutos federales y estatales diferentes, no existe una ley particular, y las decisiones anteriores se consideran específicas de los hechos ”. Siendo realistas, algunos casos legales complicados apoyan a los scrapers …
Además, la federal Computer Fraud y Abuse Act, representada como CFAA de los Estados Unidos, ha sido conocida como una ley que impone responsabilidad a aquellos que deliberadamente obtienen acceso a computadoras no autorizadas o van más allá de su acceso autorizado” Debido a esto, muchas empresas especifican la prevención de terceros que intentan recopilar datos. En 2017, hubo este caso popular – HiQ Labs vs LinkedIn, donde LinkedIn hizo uso de CFAA es que HiQ destruye su vida útil mediante usando robots en los perfiles de usuarios públicos para obtener datos. Finalmente, LinkedIn recibió la orden legal de eliminar la tecnología que impedía que HiQ Labs realizara la operación de raspado, porque no requiere autorización de acceso público para acceder a la página de perfil.
También debe mencionarse que el web scraping es un arma de doble filo y no siempre se utiliza para el bien mayor. Los ciberdelincuentes pueden arruinar la reputación de una empresa si los delincuentes la utilizan, por ejemplo, para robar contenido con derechos de autor.
Dado que no se puede determinar la intención de las personas detrás del programa deployed bots, puede ser muy difícil determinar la intención maliciosa de un programa.
Además, si los web scraping bots se vuelven más sofisticados, podrán abrirse paso aún más en aplicaciones web y API. Una instancia es el uso de IP proxy – esto incluso hará que el ataque malicioso sea más exitoso.

Estructuras vitales de un ataque (fuente)
Incluso con la forma en que se manifiestan estos problemas, Hedge funds probablemente no dejarán de adoptar el web scraping, en particular, si hay más oportunidades como acceder a oportunidades de inversión nuevas y más rentables En realidad, según una estadística, alrededor del 46 por ciento del tráfico a través de Internet es el resultado de web-scraping bots. Cuando se scrapped la web para mencionar a una determinada empresa, se puede proporcionar a los fondos de cobertura una idea muy clara de la percepción de su cliente y su perspectiva.
Con más pruebas de la importancia del web scraping para todo el uso en la industria de los fondos de cobertura, legítimamente o no, parece que nuestro mundo en línea está totalmente preparado para someterse a más análisis de forma más regular y de cerca que nunca.



发表回复