
En la era del big data, el web scraping te ayuda a ahorrar una gran cantidad de tiempo, ya que recupera automáticamente la información que necesitas en lugar de buscarla y copiarla manualmente. Sin embargo, aún necesitas raspar página tras página. El web crawler (web scraper) te permite recopilar, organizar y visitar todas las páginas presentes en la página raíz, con la posibilidad de excluir algunos enlaces.
En este blog te enseñaremos cómo funciona el web crawler y cómo construir un web crawler para extraer datos.
La Introducción de Web Crawler
Web crawler se refiere a la extracción de datos HTML específicos de ciertos sitios web. En pocas palabras, podemos percibir un web crawler como un programa particular diseñado para recopilar websites en orientación y recopilar datos. Sin embargo, no podemos obtener la dirección URL de todas las páginas web dentro de websites que contiene muchas páginas web por adelantado. Por lo tanto, lo que nos preocupa es cómo obtener todas las páginas web HTML de websites.
Recorrer Todas Las URL
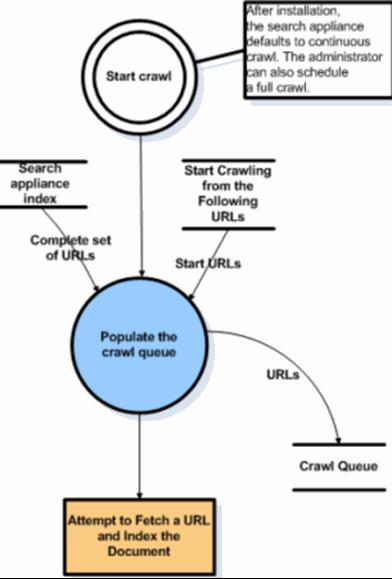
Normalmente, podríamos definir una página de entrada: una página web contiene URLs de otras páginas web, luego podríamos recuperar estas URL de la página actual y agregar todas estas URL afiliadas a la cola de crawling. A continuación, rastreamos otra página y repetimos el mismo proceso que el primero de forma recursiva. Esencialmente, podríamos asumir el esquema de crawling como búsqueda en profundidad o recorrido transversal. Y siempre que pudiéramos acceder a Internet y analizar la página web, podríamos rastrear un sitio web. Afortunadamente, la mayoría de los lenguajes de programación ofrecen bibliotecas de cliente HTTP para rastrear páginas web, e incluso podemos usar expresiones regulares para el análisis HTML.
¿Cuál es la diferencia entre el Web Crawler y el Web Scraping?
El Web Crawler, por definición, implica siempre la web. El propósito de un crawler es seguir los enlaces para llegar a numerosas páginas y analizar sus metadatos y contenidos.
El Web Scraping es posible fuera de la web. Por ejemplo, se puede recuperar información de una base de datos. El scraping consiste en extraer datos de la web o de una base de datos.
Además, los bots de web scraper pueden ignorar la presión que ejercen sobre los servidores web, mientras que los web crawlers, especialmente los de los principales motores de búsqueda, obedecerán el archivo robots.txt y limitarán sus peticiones para no sobrecargar el servidor web.
¿Cómo funciona un web crawler?
Internet cambia y se expande constantemente. Como no es posible saber cuántas páginas web hay en total en Internet, los robots de rastreo web parten de una semilla, o de una lista de URLs conocidas. Primero rastrean las páginas web de esas URL. A medida que rastrean esas páginas web, encontrarán hipervínculos a otras URL, y las añadirán a la lista de páginas que rastrearán a continuación.
Dado el enorme número de páginas web de Internet que podrían indexarse para la búsqueda, este proceso podría prolongarse casi indefinidamente. Sin embargo, un rastreador web seguirá ciertas políticas que lo harán más selectivo sobre qué páginas rastrear, en qué orden hacerlo y con qué frecuencia debe rastrearlas de nuevo para comprobar si hay actualizaciones de contenido.
Algoritmo de Web Crawler General
- Comenzar con una lista de URLs iniciales, llamadas the seeds.
- Visitar estas URLs.
- Recuperar la información requerida de la página.
- Identificar todos los hipervínculos en la página.
- Agregar los enlaces a la cola de URL, llamada frontera del crawler.
- Visitar recursivamente las URL de la frontera del crawler.
Proceso de Website Scraping
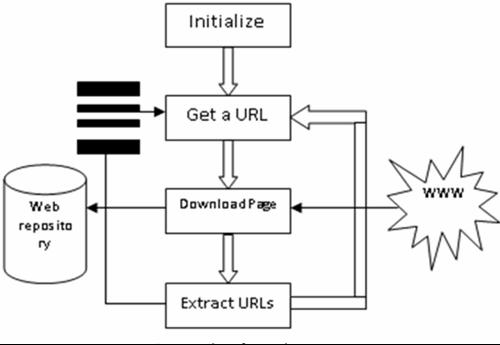
2 Pasos Principales para Construir un Web Crawler
- Para crear un Web crawler, un paso imprescindible es descargar las páginas web. Esto no es fácil ya que es necesario tener en cuenta muchos factores, por ejemplo, cómo aprovechar mejor el ancho de banda local, cómo optimizar las consultas DNS y cómo liberar el tráfico en el servidor mediante la asignación razonable de solicitudes web.
- Después de buscar las páginas web, sigue el análisis de complejidad de las páginas HTML. De hecho, no podemos obtener todas las páginas web HTML directamente. Y aquí viene otro problema. ¿Cómo recuperar el contenido generado por Javascript cuando AJAX se usa en todas partes para sitios web dinámicos? Además, la Spider Trap que ocurre con frecuencia en Internet haría un número infinito de solicitudes o puede provocar el colapso de crawler mal construidos.
Si bien hay muchas cosas que debemos tener en cuenta al crear un web crawler, en la mayoría de los casos solo queremos crear un crawler para un sitio web específico. Por lo tanto, es mejor que investiguemos a fondo la estructura de los websites de destino y recojamos algunos enlaces valiosos para realizar un seguimiento, a fin de evitar un costo adicional en las URL redundantes o basura. Además, podríamos intentar rastrear solo lo que nos interesa desde el sitio web de destino siguiendo una secuencia predefinida si pudiéramos encontrar una ruta de crawling adecuada con respecto a la estructura web.
Por ejemplo, si nos gustaría construir un web crawler para Amazon, y hemos encontrado dos tipos de páginas que nos interesan:
1. Prepara una lista de artículos, como la página principal o la URL con “/gp/new-releases o bestseller/” y etc.
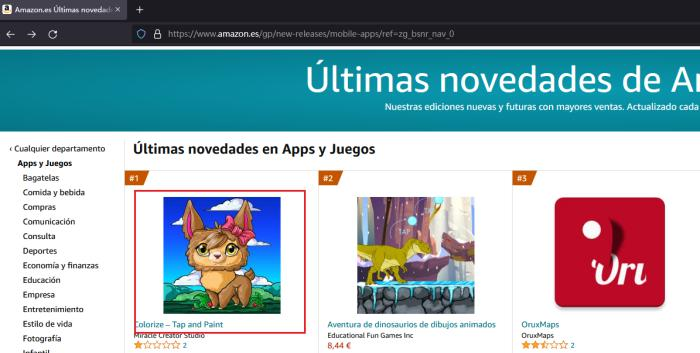
Al inspeccionar Firebug, podríamos descubrir que el enlace de cada artículo es una “Tag” en h1.
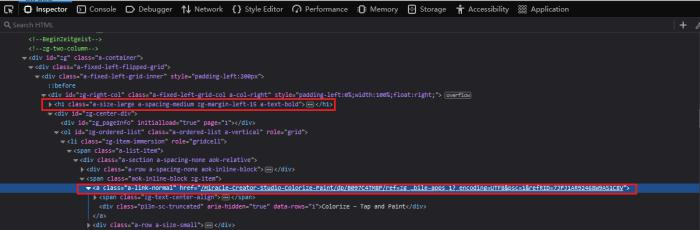
2. Contenido del artículo, como la captura de pantalla a continuación, que incluye el contenido completo del artículo.
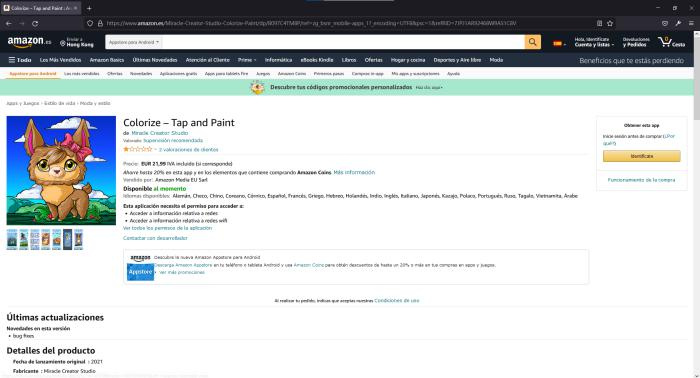
Por lo tanto, podríamos comenzar con la página principal y recuperar otros enlaces de la página de entrada. Específicamente, necesitamos definir un camino: solo seguimos la página siguiente, lo que significa que podríamos recorrer todas las páginas de principio a fin, y ser liberados de un juicio repetitivo. Luego, los enlaces a artículos concretos dentro de la página de la lista serán las URL que queremos almacenar.
Tips & Consejos para utilizar Web Crawler
- Profundidad del web crawler: Deseas que el web crawler atraviese todas las páginas. En la mayoría de los casos, una profundidad de 5 es suficiente para rastrear desde la mayoría de los sitios web.
- Rastreo Distribuido: el rastreador intentará rastrear las páginas al mismo tiempo.
- Pausa: El tiempo que el web crawler hace una pausa antes de rastrear la página siguiente.
- Cuanto más rápido configures el web crawler, más difícil será en el servidor (al menos 5-10 segundos entre clics en la página).
- Plantilla de URL: La plantilla determinará de qué páginas quieres con el crawler de los datos.
- Guardar registro: Un registro guardado almacenará qué URL se visitaron y cuáles se convirtieron en datos. Se utiliza para depurar y evitar web crawler de un sitio visitado repetidamente.
Encontrar una Herramienta para Scraping Datos
Existen desafíos tácticos importantes hoy en el mundo que viene junto con el web crawler:
- Bloqueo de direcciones IP por websites de destino
- Estructuras de web no uniformes o irregulares
- Contenido cargado con AJAX
- Latencia en tiempo real
- Sitio web Anti-Crawling agresivo
Abordar todos los problemas no es una tarea fácil, y puede ser incluso problemático. Afortunadamente, ahora no necesitas raspar un website como solía ser y quedar atrapado en un problema técnico. Alternativamente, se propone un nuevo método para recopilar data de websites de destino. No se requerirá que los usuarios manejen configuraciones complejas o codificación para construir un rastreador por sí mismos. En cambio, podrían concentrarse más en el análisis de datos en sus respectivos dominios comerciales.
Este método que mencionaría es un rastreador web automatizado – Octoparse, que hace que el crawling esté disponible para todos. Los usuarios pueden usar las herramientas y API integradas para extraer datos con una interfaz de usuario de apuntar y hacer clic fácil de usar. Se ofrecen muchas otras plantillas en esta aplicación para tratar los problemas crecientes dentro de unos pocos pasos de configuración.

Los problemas se luchan de una manera más eficiente con sus potentes funciones que incluyen:
- Servidores proxy IP para evitar el bloqueo de IP
- Herramienta Regex incorporada para volver a formatear campos de datos
- Configuración de AJAX para cargar contenido dinámico
- Servicio en la nube para dividir la tarea y acelerar la extracción, etc.
- Sitio web Anti-Crawling Agresivo
Para obtener más información sobre este web crawler, puedes ver el video a continuación para aprender cómo comenzar con software Octoparse y construir un web crawler para extraer datos fácilmente.





发表回复