
¿Por qué la gente raspa Craigslist?

Craigslist recopila información amplia. Es posible que algunos no estén satisfechos con solo navegar por él, extraen datos de Craigslist por una variedad de razones. A continuación se muestran los 4 típicos de ellos.
1> Las personas pueden extraer información de primera mano sobre casas, automóviles, computadoras y muchos más. Cuando se exporta a hojas de Excel, es mucho más fácil para ellos revisar y comparar los datos.
2> Craigslist, similar a Yellowpages y Yelp, está lleno de potenciales clientes potenciales para la generación de ingresos. Sin duda, los leads son importantes, especialmente los calificados. Esta es probablemente la razón por la que Craigslist atrae a tanta gente.
3> Obtener ganancias al revender productos. Con datos extraídos en una estructura de pozo, las personas pueden analizar mejor los precios y establecer uno nuevo para revender. Sin embargo, la reventa se encuentra más bien en el área gris, por lo que podría no ser un buen intento. A veces es rentable, pero las consecuencias pueden no ser agradables.
4> Supervisar a los competidores. Craigslist está lleno de información valiosa que cubre una variedad de industrias donde las personas pueden realizar un seguimiento de sus competidores. Estar informado de sus estrategias en tiempo real ayudará a las empresas a ganar ventaja en la competencia.
¿Es ilegal raspar Craigslist?
Como uno de los sitios web más populares para rastrear, Craigslist ha demostrado ser uno de los más difíciles. La razón es simple: a diferencia de los sitios web que brindan a los usuarios API para obtener datos, la API de Craigslist no tiene como objetivo extraer datos. Al contrario, se utiliza para publicar datos en Craigslist.
Al igual que Facebook y LinkedIn, los términos de Craigslist establecen claramente que todo tipo de robots, arañas, scripts, raspadores y rastreadores están prohibidos. Y no permitirán que las personas roben la información personal de sus usuarios en el sitio.
Craigslist ha utilizado varios métodos tecnológicos y legales para evitar que se raspe con fines comerciales. De hecho, en abril de 2017, Craigslist obtuvo una sentencia de 60,5 millones de dólares contra 3 Taps Inc, una empresa acusada de raspar listados de bienes raíces. Unos meses más tarde, Craigslist llegó a otro juicio de $ 31 millones con Instamotor, alegando que el servicio de listado de autos de Instamotor fue raspado de Craigslist, y enviaron correos electrónicos no solicitados a los usuarios de Craigslist con fines promocionales.
No obstante, como se dice en un artículo titulado 10 malentendidos sobre el web scraping, es ilegal si extraes información confidencial con fines de lucro, pero si extraes datos públicos de manera discreta para uso personal, deberías estar bien.
Cómo extraer datos de Craigslist
Si eres un programador, puedes seguir este tutorial de Python sobre cómo raspar la lista de Craigslist de East Bay Area para apartamentos. El código de este tutorial se puede modificar para extraerlo de cualquier región, categoría, tipo de propiedad, etc. O puedes consultar este tutorial de Scrapy para aprender a rastrear los trabajos de “Arquitectura e ingeniería” de Craigslist en Nueva York y almacenar los datos en un CSV expediente.
Pero el problema con los tutoriales anteriores es obvio: son demasiado complicados para los que no codifican. Si no tienes experiencia en codificación y deseas un método simple y rápido, aquí tienes un truco: use una herramienta de extracción de datos automatizada como Octoparse.
Con el poder del raspado de datos, podemos extraer toda la información que queremos de los listados de Craigslist con solo hacer clic y exportarlos a Excel, CSV, HTML y / o bases de datos fácilmente. Te guiaré a través de cómo extraer listados de bienes raíces de Craigslist en 3 pasos.
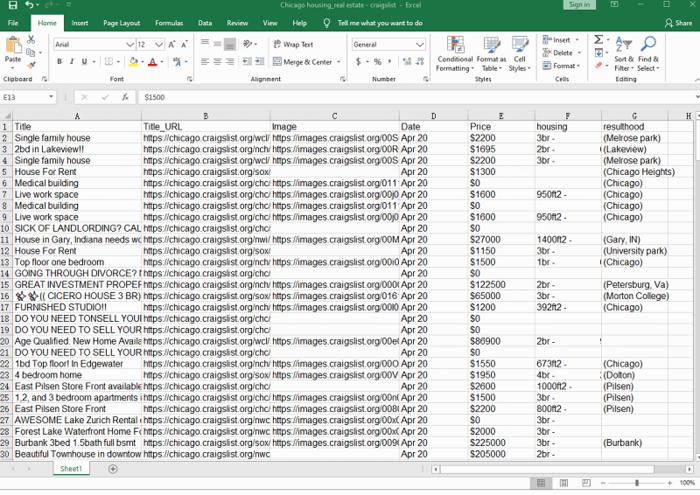
Listado de bienes raíces extraído de Craigslist
Data scraping de Craigslist con Octoparse
En este caso, vamos a raspar la vivienda / bienes raíces a la venta. Lo primero es lo primero, necesitas instalar Octoparse y ejecútalo en tu computadora.
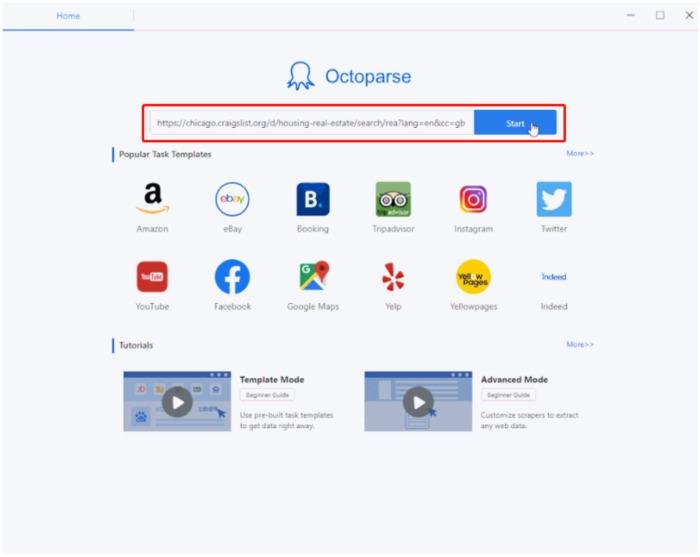
Paso 1: ingresamos la URL de Craigslist de destino para crear un rastreador
Ingresamos la URL de la lista en el cuadro y Octoparse comenzará a detectar los datos de la página automáticamente. Como puedes ver, los datos que se extraerán están resaltados en rojo y la sección de vista previa a continuación te permite editar previamente los campos de datos.
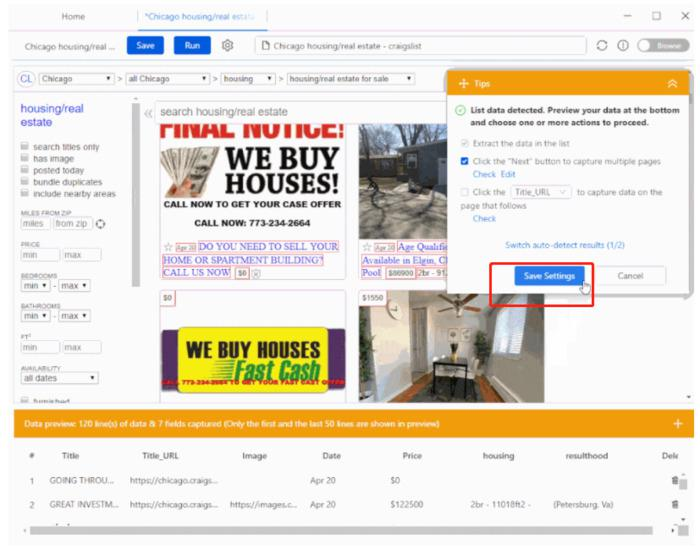
Paso 2: guardamos la configuración de extracción
Después de asegurarnos de que los campos de datos son los que queremos, hacemos clic en “Guardar configuración” y Octoparse generará automáticamente un flujo de trabajo de raspado en el lado izquierdo.
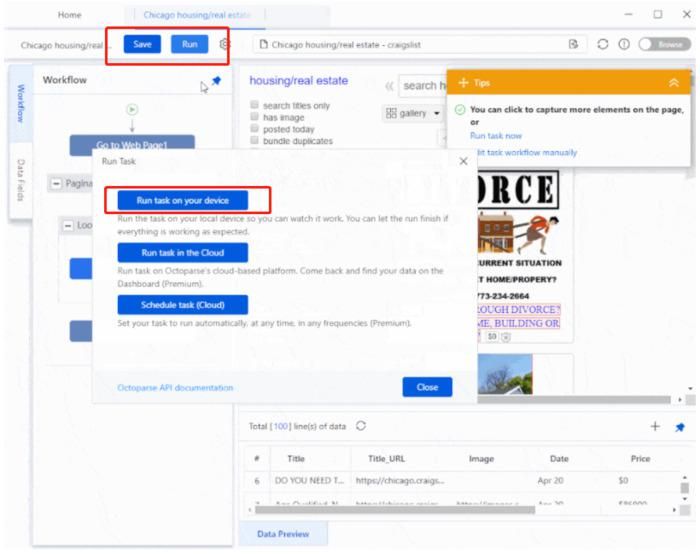
Paso 3: Ejecutamos la extracción para obtener datos
Finalmente, solo necesitas guardar el rastreador y presionar “Ejecutar” para iniciar la extracción. El proceso de raspado se puede realizar en 5 minutos.
Pensamientos finales
Tén en cuenta que a pesar de que este artículo te guía a través de la extracción de datos de Craigslist, siempre debes respetar sus Términos de servicio y rastrear con una frecuencia moderada.
Las herramientas de extracción de datos no solo pueden raspar todas las listas de Craigslist, sino que también se utilizan en muchos escenarios, incluidos marketing, comercio electrónico y venta minorista, ciencia de datos, investigación financiera y de equidad, periodismo de datos, académico, gestión de riesgos, seguros y muchos más. Puedes leer sobre los usos del web scraping en los negocios en este artículo: 25 trucos para hacer crecer tu negocio con la extracción de datos web.



发表回复