
La necesidad de extraer datos de los sitios web aumenta día a día, ya sea en el sector tradicional de los servicios o en el actual sector del comercio electrónico, en rápido crecimiento. Siempre existe la necesidad de recopilar datos de sitios web con python cuando trabajamos en proyectos relacionados con datos, como el seguimiento de precios, la analítica empresarial o la agregación de noticias.
Sin embargo, copiar y pegar los datos línea por línea se ha quedado obsoleto, y es entonces cuando se suele mencionar y utilizar python, un lenguaje de programación relativamente antiguo.
En este artículo, le enseñaremos cómo convertirse en un experto en minería de datos web, que es web scraping con python.
¿Qué es Python?
Python es un lenguaje de programación que permite realizar funciones automatizadas de recopilación y resumen de datos con una sencilla escritura de código.
Descripción del Web Scraping
La técnica web scraping puede ayudarnos a transformar datos HTML no estructurados en datos estructurados en una hoja de cálculo de Excel o base de datos. Se puede usar Python para escribir códigos, acceder a los datos del sitio web con la API o herramientas de extracción de datos como Octoparse, cuales son las opciones generales para el web scraping.
Veamos las herramientas del web scraping:
30 Mejores Softwares Gratuitos de Web Scraping en 2023
¿Para qué sirve el Web Scraping?
Comparación de precios: Servicios como Octoparse utilizan el raspado de la web para recoger datos de sitios web de compras en línea y utilizarlos para comparar los precios de los productos.
Recopilación de direcciones de correo electrónico: Muchas empresas que utilizan el correo electrónico como medio de marketing, aplican el web scraping para recoger el ID de correo electrónico y luego enviar correos electrónicos por lotes.
Social Media Scraping: El web scraping se utiliza para recopilar datos de sitios web de medios sociales como Twitter o LinkedIn para averiguar qué es tendencia y la generación Lead.
Investigación y desarrollo: El web scraping se utiliza para recoger un amplio conjunto de datos (estadísticas, información general, temperatura, etc.) de sitios web, que se analizan y utilizan para realizar encuestas o para I+D.
Listados de empleo: Los datos relativos a las ofertas de empleo y las entrevistas se recopilan de diferentes sitios web y se enumeran en un solo lugar para que el usuario pueda acceder fácilmente a ellos.
¿Se puede hacer web scraping con la API?
Para algunos sitios web grandes como Airbnb o Twitter, proporcionan API para que los desarrolladores accedan a sus datos. La API significa interfaz de programación de aplicaciones, que es el acceso para que dos aplicaciones se comuniquen entre sí. Para la mayoría de las personas, API es el enfoque más óptimo para obtener datos proporcionados por el propio sitio web.
Sin embargo, la mayoría de los sitios web no tienen servicios API. A veces, incluso si proporcionaran API, los datos que podrías obtener no serían los que deseas. Por lo tanto, escribir una secuencia de comandos de Python para crear un rastreador web se convierte en una solución poderosa y flexible.
Pero, ¿Por qué deberíamos usar python en lugar de otros idiomas?
- Facilidad de uso: Python es sencillo de codificar en el proceso de web scraping. No hay que añadir puntos y comas “;” ni llaves “{}” en ningún sitio. Esto hace que sea menos complicado y fácil de usar.
- Flexibilidad: Como sabemos, los sitios web se actualizan rápidamente. No solo el contenido sino también la estructura web cambiarían con frecuencia. Python es un lenguaje fácil de usar porque es dinámicamente imputable y altamente productivo. Por lo tanto, las personas pueden cambiar su código fácilmente y mantenerse al día con la velocidad de las actualizaciones web.
- Gran colección de bibliotecas: Python tiene una enorme colección de bibliotecas como Numpy, Matlplotlib, Pandas, etc., que proporciona métodos y servicios para diversos fines. Por lo tanto, es adecuado para el raspado de la web y para la manipulación posterior de los datos extraídos.
- Potente: Python tiene una gran colección de bibliotecas maduras. Por ejemplo, las solicitudes, beautifulsoup4 podrían ayudarnos a obtener URL y extraer información de las páginas web. Selenium podría ayudarnos a evitar algunas técnicas anti-scraping al dar a rastreador web la capacidad de imitar comportamientos de navegación humanos. Además, re, numpy y pandas podrían ayudarnos a limpiar y procesar los datos.
- Código pequeño, tarea grande: El web scraping se utiliza para ahorrar tiempo. Pero, ¿de qué sirve si se pasa más tiempo escribiendo el código? Pues no hace falta. En Python, puedes escribir códigos pequeños para hacer tareas grandes. Por lo tanto, se ahorra tiempo incluso mientras se escribe el código.
¡Ahora comencemos nuestro viaje en web scraping usando Python!
Paso 1: Importar la biblioteca de Python
En este tutorial, te mostraremos cómo scrapear las reseñas de Yelp con Python. Utilizaremos dos bibliotecas: Beautiful Soup en bs4 y request en urllib. Estas dos bibliotecas se usan comúnmente en la construcción de un rastreador web con Python. El primer paso es importar estas dos bibliotecas en Python para que podamos usar las funciones en estas bibliotecas durante el web scraping.

Paso 2: Extraer el HTML de la página web
Necesitamos extraer comentarios de “Milk & Cream Cereal Bar” de Yelp. Primero, guardemos la URL en una variable llamada URL. Entonces podríamos acceder al contenido de esta página web y guardar el HTML en “ourUrl” utilizando la función urlopen() en la solicitud.

Luego aplicamos BeautifulSoup para analizar la página web.

Ahora que tenemos la “soup”, que es el HTML sin formato para este sitio web, podríamos usar una función llamada prettify() para limpiar los datos sin procesar e imprimirla para ver la estructura anidada de HTML en la “soup”.
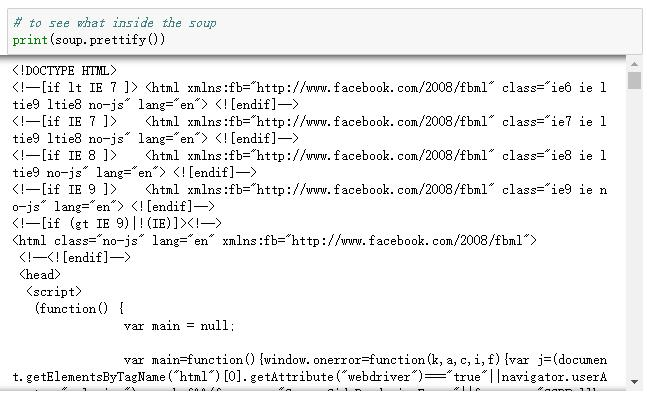
Paso 3: Ubicar y Scrapear las reseñas
Para hacer web scraping de Yelp con Python, a continuación, deberíamos encontrar las reseñas HTML en esta página web, extraerlas y almacenarlas. Para cada elemento en la página web, siempre tendrían una “ID” HTML única. Para verificar su ID, necesitaríamos INSPECT en una página web.
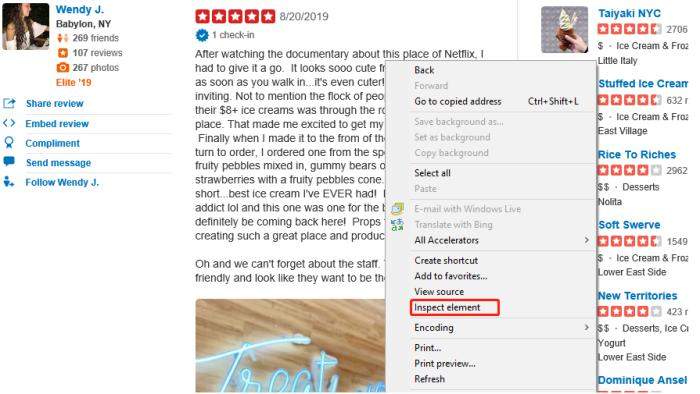
Después de hacer clic en “Inspeccionar elemento” (o “Inspeccionar“, depende de diferentes navegadores), podemos ver el HTML de las revisiones.

En este caso, las revisiones se encuentran debajo de la etiqueta llamada “p“. Entonces, primero usaremos la función llamada find_all() para encontrar el nodo padre de estas revisiones. Y luego ubicamos todos los elementos con la etiqueta “p” debajo del nodo padre en un bucle. Después de encontrar todos los elementos “p”, los almacenamos en una lista vacía llamada “review”.
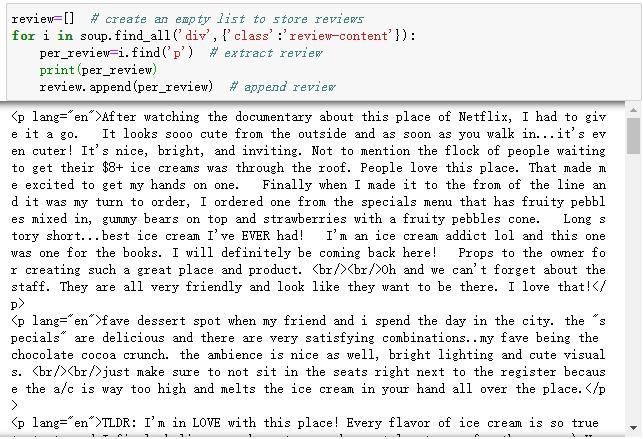
Ahora tenemos todas las reseñas de esa página. Veamos cuántas reseñas hemos extraído con Python.

Paso 4: Limpiar las reseñas
Debemos tener en cuenta que todavía hay algunos textos inútiles como “<p lang=’en’>” al comienzo de cada revisión, “<br/>” en el medio de las revisiones y “</p>” en Fin de cada revisión.
“<br/>” representa un salto de línea simple. No necesitamos ningún salto de línea en las revisiones, por lo que tendremos que eliminarlos. Además, “<p lang=’en’>” y “</p>” son el principio y el final del HTML y también debemos eliminarlos.

Finalmente, obtenemos con éxito todas las revisiones limpias con Python con menos de 20 líneas de código.
Aquí hay solo una demostración para scrapear 20 comentarios de Yelp. Pero en casos reales, es posible que tengamos que enfrentar muchas otras situaciones.
Por ejemplo, necesitaremos pasos como la paginación para ir a otras páginas y extraer los comentarios restantes de esta tienda. O también tendremos que extraer otra información como el nombre del revisor, la ubicación del revisor, el tiempo de revisión, la calificación, el check-in ……
Conclusión
Para implementar la operación anterior y obtener más datos, necesitaríamos aprender más funciones y bibliotecas como el selenium o la expresión regular. Sería interesante pasar más tiempo profundizando web scraping con Python.
Sin embargo, si estás buscando algunas formas simples de hacer web scraping, Octoparse podría ser tu solución. Octoparse es una poderosa herramienta de web scraping que podría ayudarte a obtener fácilmente información de sitios web.
¡No dudes en contactarnos(support@octoparse.com) cuando necesites una poderosa herramienta de web scraping para tu negocio o proyecto!





发表回复